使用首字母缩略词比可以解释的速度更快,每个IT操作都有他们最喜欢的MTT-Fill-In-Blank。通常,这些平均时间与咧嘴笑容刷掉,简单,“肯定是有道理的。”对于我们大多数人来说,这些MTT的许多人背后的想法是他们提供了一种介绍一些讨论某种优化的媒介,通常在关键业务功能的可用性的上下文中。
即使早期版本的平均故障间隔时间(MTBF)被用来表明机器的可靠性,许多行业已经产生了他们自己的测量来帮助表明优化领域。因此,IT操作空间有自己的变化,下面的图片试图描述最常用的重要业务服务的平均时间,并在下面进行简要说明。
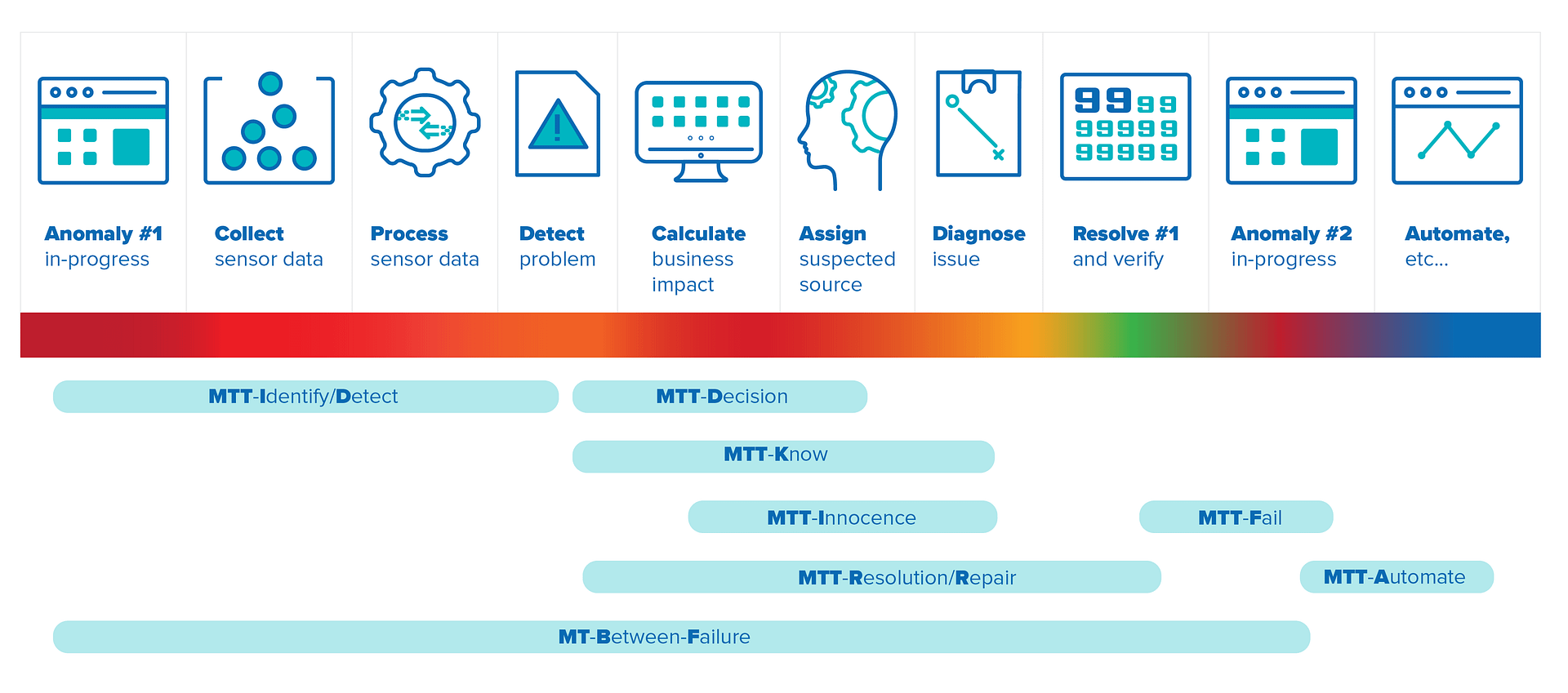
- MTTI / MTTD- 识别(或平均检测时间)的平均时间
经过一段时间来表示环境中发生了问题 - MTTD- 指定决定的时间
在决定处理检测到的问题之前经过的时间 - MTTK-是时候知道了
在确定问题的根本原因之前经过的时间 - MTTI- 意味着纯真
独立IT群体宣称商业停机的时间不在他们的地区 - MTTF-平均失败时间
从解决一个问题到出现下一个问题所经过的时间 - MTTR- 分辨率的平均时间(或平均修复时间)
检测到该问题后,修复该问题所需的时间
注意:另一种选择是一旦确定了业务影响就开始度量,因为问题可能被认为是非关键的,并在以后解决。 - MTTA-平均自动化时间
使用自动化崩溃各个阶段所需的时间来修复以前的问题 - 平均故障间隔- Mean Time Between Failure
经典的时间从一个问题到另一个问题
毫无疑问,对其中一些界限有一些辩论,但希望它是在可用性和正常运行时间内进行生产性对话的起点。虽然不同的IT运营管理(ITOM)产品专注于改善不同方面,但最终回报是消除中断。随着软件定义的IT操作试图将机器学习和人工智能注入IT生态系统,对自动化的关注将导致最终用户的零可察觉的故障。换句话说,数据中心的自我修复性质将为关键业务系统的用户提供始终如一的现实。
如果您有兴趣了解高级IT企业如何利用最新的ITIM平台来减少MTT-anything,请考虑加入我的行列GalaxZ18。